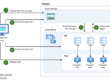
Modelové serverové struktury
Úvod
V tomto článku si dnes popíšeme ukázky modelových serverových struktur. Budeme si trochu hrát s konfigurací a modelováním různého počtu kousků hardware, a budeme přihlížet k tomu, co se z toho dá tvořit. Pro jednoduchost nebudeme vůbec řešit networking při modelování našich struktur.
Pro práci s modely budeme pracovat s těmito pojmy:
- Server
- NAS
- SAN
Definice komponent
Pro přehlednost zde je tabulka shrnující naši definici základních komponent:
| Název komponenty | Compute | Účel Storage |
|---|---|---|
| Server | Vysoký | Lokální/sdílený |
| SAN | nízký | Dimenzovaný pro vysoké iops |
| NAS | nejnižší | Pro zálohování dat |
A od této aproximace poté si budeme definovat různé struktury a jejich formy uspořádání. Níže je komentář ke komponentám
Server
Serverem budeme nazývat jakoukoliv komponentu, která dokáže dodat výpočetní výkon, ale umožní i práci s polem. Jinými slovy compute + storage.
SAN
Podobně jako u NAS i SAN bude definované jako komponenta, která slouží primárně jako storage, ale má vyšší compute.
NAS
NAS budeme nazývat komponentu, která bude sloužit pouze jako storage a bude mít velmi slabý compute.
Definice ohrožení infrastruktury a popis tabulky sumací
V rámci infrastruktury nás ohrožuje několik jevů, které budeme při hovoření o strukturách vyhodnocovat jako naše KPI. Tyto jevy jsou:
- Identifikace SPOF
- Výpadek jednoho prvku
- Útok na virtuální stroje (ransomware)
- Výpadek hypervizoru či obecněji výpadek primární lokality.
- Stabilita záloh – pravidlo 3-2-1.
- Rychlost obnovy záloh.
V tabulkách sumací budeme-li hovořit o umístění prvků do různých lokalit, zkratka DR značí disaster recovery, čili obecně nějaká druhá geograficky oddělená lokalita, ať už v jiné budově, nebo v jiném městě, či státě. V rámci vyhodnocování budeme modelovat různé formy ohrožení struktur s výpisem akčního plánu, co dělat. Při stresování struktury budeme vždy uvažovat jen jeden izolovaný jev, nepočítáme s řetězením více událostí současně. Pro jednoduchost vypouštíme výpadky internetu, networking a výpadky disků.
Úvod o kombinatorice prvků
Možné struktury jsou závislé na počtech jednotlivých komponent a jejich uspořádání. My si zde vypíšeme nejzajímavější struktury s patřičným okomentováním, dodáme jejich potřebnou modifikaci tak, abychom dosáhli modelového ideálu a poté vyhodnotíme výhody a nevýhody. Pokud bychom byly opravdu důslední, provedeme kombinaci všech prvků se všemi, to bychom pak pro 4 strojový setup realizovali srovnání 64 variant, což není cílem tohoto článku a spíše bychom čtenáře zahlcovali nadbytečnými informacemi. Proto se omezíme jen na některé populární a velmi často užívané struktury, konkrétně:
- Základní struktura
- HA
- Cluster
- Server-storage
Výše uvedené struktury jsou seřazeny podle ceny. Nejlevnější je základní struktura, nejdražší pak Server-storage. Názvosloví není odvozeno z literatury, ale vychází z praxe a pro potřebu tohoto článku.
Základní struktura
Popis
Základní strukturou je Server-NAS. Jedná se o typický setup v malých a středních firmách, kde server nese compute a lokální storage dohromady a data z lokálního storage jsou zálohována na NAS. Nejvýhodnější umístění prvků je následující:
| Prvek | Lokalita |
|---|---|
| Server1 | Primár |
| NAS1 | DR |
Idealizace modelu
V ideálním případě je samotná NAS zálohována dle pravidla 3-2-1.
Tabulka scénářů výpadku
| Možná forma útoku | Očekávaná akce |
|---|---|
| Útok na virtuální stroje | Lze provést obnovu záloh z NAS v řádech minut či hodin |
| Výpadek primární lokality/výpadek hypervizoru | Nefunkční struktura, je potřeba mít plán pro obnovu do cloudu, nebo mít možnost zápůjčení serveru a provést v řádech hodin obnovu na nový stroj |
| Výpadek NAS | nefungují zálohy, služby na serveru fungují |
V případě, kdy Server i NAS jsou ve stejné lokalitě a dojde k pádu primární lokality, nebo absencí pravidla filozofie zálohování typu 3-2-1, dochází k nevratné ztrátě dat a celé infrastruktury. Tento model je levný, u mnoha malých firem naprosto dostatečný i s nevýhodami, které přináší. Daný disaster recovery plán je pokryt rozumnou servisní smlouvou s externí společností zajišťující IT služby.
HA failover
Popis
HA je velmi častý setup ze dvou serverů.
Jedná se o oboustrannou replikaci, kdy jeden stroj je definován jako primární stroj (server1), druhý jako sekundární (server2). V případě výpadku primárního stroje přebírá sekundární stroj funkci primárního. Při obnově primárního stroje se naopak přesune diferenciál dat ze sekundáru na primární stroj.
Mezi takové aplikace ve světě Proxmox poslouží nástroj typu PVE-ZSync, který na ZFS umí zajistit repliky.
With the Proxmox VE ZFS replication manager (pve-zsync) you can synchronize your virtual machine (virtual disks and VM configuration) or directory stored on ZFS between two servers. By synchronizing, you have a full copy of your virtual machine on the second host and you can start your virtual machines on the second server (in case of data loss on the first server).
Alternativně také pak můžeme na dvoustrojové struktuře utvořit replikovaný storage pomocí GlusterFS, který nám pouze replikuje storage, nikoliv setup. Když trochu zkonvergujeme mimo, tak platí následující evoluce technologií v posloupnosti jak je psáno:
DRBD < GlusterFS < CEPH
Každá vznikala v určité době, kdy vládli na trhu určité trendy a společně realizují podobné, jen jinými způsoby.
Idealizace modelu
V této struktuře nazývanou jako HA není zohledněno zálohování. Proto umístěním jedné NAS opět dle zálohovací filozofie 3-2-1 získáváme velmi stabilní strukturu. Další nutnou potřebou je použití těchto dvou serverů jako master/slave a jejich rozmístěním do různých lokalit. Tedy primární server umístíme do hlavní lokality, je to náš produkční stroj a druhý server – standby umístíme do DR (disaster recovery) lokality. Tím získáváme opravdu vysokou odolnost struktury. Zde je přehledná tabulka:
| Prvek | Lokalita |
|---|---|
| Server1 | Primár |
| Server2 | DR |
| NAS1 | Mimo DR i primár |
Tabulka scénářů výpadku
V této struktuře se náročně hledají nevýhody. Jedná se totiž o velmi stabilní strukturu zajišťující ochranu před všemi formami útoků:
| Možná forma útoku | Očekávaná akce |
|---|---|
| Útok na virtuální stroje | Lze provést obnovu záloh z NAS v řádech minut či hodin |
| Výpadek primární lokality | Roli přebírá druhý stroj |
| Výpadek NAS | nefungují zálohy, služby na serverech fungují |
| Výpadek DR | nic se neděje |
Hlavní potenciální riziko je, že pokud by byl proveden ransomware útok na hypervizor specificky, tak by došlo k jeho přenosu na oba stroje, protože tato HA struktura má mezi sebou vyměněné SSH klíče a mají vzájemně root přístupy, tedy takový ransomware na Server1 by se mohl přenést snadno na Server2. Potenciální prevencí je zakázat přístupy na server z jiných míst než mgmt VLAN, nasadit port knocking na SSH či jinou formu ochrany. Další obecnou nevýhodou této struktury je nízký compute. Utilizujeme dva stroje a tedy 50% výpočetní kapacity užíváme ve prospěch redundance.
Cluster struktura
Popis
Cluster je definovaný o minimu 3 soustrojí, které sdílejí společnou konfiguraci a vyměňují si opět mezi sebou data přes root oprávnění přes SSH klíče podobně jako HA struktura. Cluster může a nemusí mít sdílený storage. O sdíleném storage je napsán samostatný článek na našem blogu na který odkazujeme. Porovnáme-li cluster a HA strukturu, hlavní rozdílnost je v Compute. Cluster jednoduše nabízí vyšší výpočetní výkony než HA struktura. V této výpočetní struktuře v případě nasazení CEPH s přidáváním dalších serverů roste jak výpočetní výkon, tak kapacitní výkon tak i datový výkon. Takový modelový příklad, kdy jsme zvolili konverze ze Server-storage na CEPH v jednom z referenčních pracovních článků. Důvody, proč jsme zvolili na první pohled „downgrade“ ze Server-storage na CEPH budou zřejmé po přečtení sekce Server-storage.
Idealizace modelu
Pro soustrojí cluster platí velmi podobné vztahy jako pro HA strukturu. Aby byl model opravdu kvalitní a stabilní, je potřeba mu dodat nejen patřičné zálohování, ale i zajistit DR plán. V případě nasazení CEPH je doporučený setup pro souservří číslo 4. Tři Servery jsou minimální funkční setup, čtyři jsou doporučené setup.
V případě clusteru dává smysl nasazení ne konvenčního zálohování dostupného v PVE, ale je lepší kvůli rychlosti a dalším benefitům (offload CPU zátěže) použít Proxmox backup server, který si můžeme dosadit jako formu našeho modelu definovaného písmeny NAS. Také musíme zajistit zálohování clusteru a mít další, sekundární cluster v DR lokalitě, ideálně síťově oddělený tak, jak je uvedeno v našem konkrétním nasazení. Jedině tak lze docílit velmi stabilní struktury, bezpečně pro produkčního nasazení. Jakékoliv zanedbání jedno z jevů vede k nestabilitě struktury.
Pak tedy distribuce prvků dle lokalit bude:
| Prvek | Lokalita |
|---|---|
| Server1 | Primár |
| Server2 | Primár |
| Server3 | Primár |
| NAS1 | DR/třetí lokalita |
| Server4 | DR |
| Server5 | DR |
| Server6 | DR |
Mezi clustery lze provést repliku dat v reálném čase použitím různých řešení, pomocí CEPH je to mirroring například. Tento proces poté významně navyšuje rychlost obnovy z řádů hodin na řády minut. Také NAS1 můžeme nechat replikovat na NAS2, čímž se významným způsobem zvýší retence a kvalita záloh a také se zajistí dvojí bezpečí, kdyby došlo k infekci clusteru.
Tabulka scénářů výpadku
| Možná forma útoku | Očekávaná akce |
|---|---|
| Útok na virtuální stroje | Lze provést obnovu záloh z NAS v řádech hodin, v případě použití mirroringu se jedná o řády minut |
| Výpadek primární lokality | Roli přebírá druhá lokalita manuálně obnovou z NAS1 nebo nahozením mirroru |
| Infekce clusteru | Obnova pomocí NAS |
| Výpadek jednoho serveru | Je udrženo quorum, compute běží |
| Výpadek NAS1 | nefungují zálohy, služby na serverech fungují |
| Výpadek DR | nic se neděje |
Server-storage
Popis
Poslední významnou, a velmi stabilní strukturou je Server-storage a to už v minimálním setupu 2×2, tedy 2x Server a 2x storage. V tomto případě se jedná o soustrojí čtyřserverové, kdy výpočetní výkon je dedikován na Servery, a práce s datovým polem je dedikována na Storage. Tímto logickým oddělením získáváme vysoký výpočetní výkon a současně vysoký datový výkon.
Daná struktura tedy redundancí neztrácí serverově na výpočetním výkonu, ale na úrovni Storage ztrácí 50% kapacitu pole ve prospěch redundance. Daná struktura je poté vysoce stabilní, ale také jedna z nejnákladnějších struktur, jak si ukážeme za chvíli.
Idealizace modelu
Pro idealizaci modelu musíme do čtyřstrojí umístit několik dalších prvků, abychom docílili opravdu stabilní struktury. V ideálním případě je počet serverů nikoliv 2, ale alespoň 3, aby bylo dosaženo quorum. Dvouserverová struktura tedy není celkově vyhovující, je pouze minimální přípustná. Pro Storage je poté nutné mít SAN, které umí funkci vysoké dostupnosti. Tedy podobně jako platilo u dvoustrojové struktury typu HA mezi dvěma servery, tak to stejné musíme zajistit mezi dvěma SAN. Tuto funkcionalitu HA buď dodávají výrobci, nebo nebo případě TrueNAS je to příplatková služba. Tedy zde záleží na kvalitě pole a dalších parametrech, které nejsou součástí tohoto srovnání dále.
Pro SAN platí, že je vhodné mít funkci snapshotů pole v pravidelných intervalech. Tato funkcionalitě je opět buď záležitostí výrobců či vlastností filesystému.
Tedy ideální rozložení komponent je následující:
| Prvek | Lokalita |
|---|---|
| Server1 | Primár |
| Server2 | Primár |
| Server3 | Primár |
| SAN1 | Primár |
| SAN2 | Primár |
| NAS1 | DR/třetí lokalita |
| Server4 | DR |
| Server5 | DR |
| Server6 | DR |
| SAN3 | DR |
Jak vidíme, optimální počet komponent ve struktuře je 10. Proto se také jedná o nejnákladnější strukturu vůbec, která na druhou stranu přináší hlavní benefitů oproti Cluster struktuře v tom, že má dedikovaný storage a tedy vysokou datovou i iops kapacitu.
Tabulka scénářů výpadku
| Možná forma útoku | Očekávaná akce |
|---|---|
| Útok na virtuální stroje | Lze provést obnovu záloh z NAS v řádech hodin, v případě použití snapshotingu na SAN se jedná o obnovu v řádech minut |
| Výpadek primární lokality | Roli přebírá druhá lokalita obnovou repliky |
| Infekce hypervizoru | Obnovujeme pomocí NAS |
| Výpadek jedné SAN | Roli přebírá druhá SAN |
| Výpadek jednoho serveru | quorum je zachováno, compute běží |
| Výpadek NAS1 | nefungují zálohy, služby na serverech fungují |
| Výpadek DR | nic se neděje |
Tabulka se sumací struktur
tím jsme probrali všechny struktury a zde je poté krátká tabulka se sumací definice minimálního počtu prvků a optimálního počtu komponent.
| Počet prvků | Název uspořádání | Optimální počet komponent |
|---|---|---|
| 1 | Základní | 2 |
| 2 | HA | 3 |
| 3 | Cluster | 7 |
| 4 | Server-storage | 10 |
Do této chvíle jsme hovořili o strukturách ideálních a všechny struktury Connectica s.r.o. realizovala ať už s dodávkou hardware, nebo i networkingem. Z praxe vždy nacházíme rozdílnosti mezi ideální strukturou a tím, co má zákazník za hardware dostupný, nebo jaké má finanční možnosti. Pro realizaci práce kvalitně je potřeba dodržet obě podmínky, tedy jak mít dostatečné možnosti financování, tak mít dostupnost dostatečně kvalitního hardware. Zde v praxi nejčastěji vznikají různé třecí plochy, nebo neporozumění. Klient si přeje Server-storage, ale nemá na to dostatečné možnosti financování jak danou strukturu zrealizovat kvalitně. Většinou pak požaduje nižší financování, které je uměle vynucováno formou výběrových řízení čímž vzniká tlak na co nejnižší cenu. Takové kompromisy v ceně ale nejsou kompromisy, jsou to pouze ústupky, které nesou v budoucnu problémy s tím, že dané struktury jsou dodávány nestabilní, protože se většinou vypouští některý z esenciálních procesů. Pokud bychom vzali Server-storage strukturu, tak taková nevhodná nabídka má na úkon nižší ceny absence typu:
- Snížení ceny uměle tím, že se odstraní proces zálohování tedy nedodá se NAS komponenta, nebo se dodá nějaká low-cost varianta, která nesedí do modelu efektivně.
- Cluster je složen ze dvou serverů, ne tří serverů.
- Komponenty pro DR lokalitu se kompletně vypouští a nerealizují se.
- Místo trojservří se dodává jeden Server a jeden SAN do DR
- Místo trojservří na primáru se dodá jen dvojservří.
- SAN není v HA
- SAN neumí HA, nebo umí ale za příplatek, který není zohledněn v nabídce účelově.
Podobné situace jsou běžné, a je to vždy o daném tržním prostředí. Klient chce co nelevnější strukturu, obchodník mu vychází vstříc tím, že vypouští nějaké části procesu, aby měl šanci být vůbec součástí výběrového řízení. Dodaná vyhraná zakázka pak nesplňuje podmínky kvality, ale je levná, což pak znamená, že finanční ředitel od zákazníka to dobře uhádal, ušetřil firmě 500 000 kč, je to pašák. Je to na první pohled pozitivní jev pro všechny, bude totiž na prémie a bude lepší příspěvek na teambuildingy. Ale za 2 roky, až ve firmě dojde k infekci clusteru, celá firma kvůli této úspoře týden nepojede, protože není možnost jak udělat obnovu záloh rychle i kvalitně a ztráty ve firmě z nefunkční infrastruktury budou v řádech převyšující tuto úsporu několikanásobně. Vina se většinou svaluje na mizerného dodavatele, který dodal nekvalitní strukturu a vypustil amatérsky nějaké části komponent, které se stali pro zákazníka osudné.