Jeden z nejčastějších problémů na Linuxových strojích, který má přímou souvislost s diagnostikami nízké propustnosti je právě práce s přetížením jádra (dále CPU load). Před samotnou diskuzí ohledně problematiky je potřeba se podívat na to, co je to load.
1. CPU load v kostce
CPU load udává průměrnou hodnotu kolik procesů čeká ve frontě na svoji příležitost být spočítáno jádrem.
CPU load je vyjádřen v číselných jednotkách a typicky se pohybuje někde v okolí hodnot 1-50. Na výstup konkrétního loadu konkrétního serveru stačí zadat příkaz uptime
➜ ~ uptime
12:55 up 1 day, 3:51, 1 user, load averages: 1.76 1.81 1.61
V příkazu se nachází tři hodnoty zprůměrovaného loadu a to:
- Průměrný load za 1 minutu
- Průměrný load za 5 minut
- Průměrný load za 15 minut
Takto nám dokáže každý linuxový stroj ukázat fluktuaci loadu v čase a z toho můžeme snadno usoudit, zdali před 15 minutami nebyla nějaká divoká vlna CPU load, která nám vytížila server.
Hodnota loadu je proměnlivá a platí, že když je load = 1, tak právě jeden výpočet je s daným CPU svázán a je na něm počítán. Máme-li 8 jádrový procesor a load je na hodnotě 1, tak to znamená, že každé z těch 8 jader je vytíženo právě jedním procesem. Pro doplnění dodáváme, že čistě hypoteticky, když load=0 tak to znamená, že systém se kompletně fláká.
1.2 jak moc vysoká hodnota loadu je dostatečně vysoká?
Na tuto otázku neexistuje jednoduchá odpověď. Ono to prostě závisí. Může být hodnota load ekvivalentní číslu 50 a systém je kompletně svižný, ale může být hodnota loadu 10 a systém bude kompletně nepoužitelný. Tedy obecně čím nižší hodnota loadu, tím lépe. Ideální je, když je load po většinu času okolo hodnoty 1.
To, na čem opravdu závisí při debugování systému není to, jaká je hodnota loadu, ale proč je hodnota taková, jaká je. Jsou obecně tři způsoby, co způsobuje, že je je CPU load vysoký:
- CPU bounded load – Load v důsledku vytížení jádra (Nestíhá jádro)
- OOM load – Load v důsledku nedostatečné RAM
- I/O Load – Load v důsledku vysokého I/O (Disky to nedávají)

1.3 TOP command a jeho výstup
Příkaz top slouží pro vizualizaci linuxových procesů. Po jeho zadání vidíme mnoho informací, některé jsou spíše informativní (uptime, počet userů). Zde je pouze výše začátku hlavičky top příkazu
top - 13:13:18 up 11 days, 12:55, 2 users, load average: 0.00, 0.00, 0.00
Tasks: 126 total, 1 running, 125 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 1.6 sy, 0.0 ni, 98.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 1946.2 total, 92.6 free, 131.9 used, 1721.6 buff/cache
MiB Swap: 3814.0 total, 3455.1 free, 358.9 used. 1615.9 avail Mem
Kromě toho vidíme i výpis různých jaderných procesů
%Cpu(s): 1.6 us, 0.0 sy, 0.0 ni, 98.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
kde zde je vysvětlení následujících zkratek u %CPU :
us: user CPU time. Zde je v procentech vyobrazeno, kolik jaderného výkonu užívají jádra pro potřebu nějakého z uživatelů systému. Typicky to mohou být třeba Apache, nebo MySQL či nějaký shellový skript. Pokud je hodnota user CPU vysoká, je to CPU bounded load problém.
sy: System CPU time. Čas užitý pro systémové výpočty, většinou je to něco co počítá samotný kernel. Pokud je hodnota system CPU vysoká, je to CPU bounded load problém.
id: CPU ide time. Čas, kdy by procesor mohl něco dělat ale nedělá nic. Lidově řečeno, když se CPU fláká. Zde paltí, čím více procent CPU idle, tím lépe.
wa: CPU I/O wait. Čas, kdy procesor chce něco počítat, ale nemůže, protože čeká než proběhne nějaký zápis nebo četba. Když je tato hodnota vysoká, je to často problém s disky.
2. Tři hlavní faktory diagnostiky loadu
2.1 CPU bounded load
Tento druh loadu je v dnešní době už poměrně zanedbatelný a je to z toho důvodu, že exponenciálně roste vývoj i dodávání vysoce naddimenzovaných serverových procesorů na trh a ke koncovým spotřebitelům. I tak, setkáme se s ním, třeba typicky na sdíleném hostingu, u levných VPS nebo u nevhodně napsaných programů. CPU bounded problém identifikujeme velmi snadno, kromě toho, že nám napoví vysoká hodnota user CPU time a vysoká hodnota yystem CPU time, tak dále v příkazu top uvidíme konkrétní proces, který vytěžuje jádro u %CPU hodnoty
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
24475 root 20 0 246m 66m 3504 S 90 0.7 0:00.91 update_conf.pl
3911 mysql 20 0 1932m 374m 7664 S 1 3.7 8:27.17 mysqld
V tomto případě vidíme, že nějaký shellový skript co běží pod rootem s názvem updateconfpl bere 90% výpočetních zdrojů. U CPU bounded loadu jsou dva jevy, které mohou nastat:
- Jeden proces vytěžuje jedno konkrétní jádro na 99%
- Více procesů soupeří o jedno jádro.
V obou případech je to poměrně snadno viditelné v top příkazu k identifikaci a řešení je snadné – stačí přidat výpočetní prostředky mašině a je to. Na závěr jen poznatek, pokud je nějaká aplikace psána jako vícevláknová, může dojít k tomu, že program utvoří na jedno CPU více vláken a tím zahltí také CPU, což povede ke zvýšenému loadu a to i přesto, že v topu nebudou vidět konkrétní procesy, který by jádro vytěžovali.
2.2 Out of memory load
Další z důvodů vysokého loadu je přesycení RAM, což typicky vyústí v to, že systém začně hodně swapovat. Protože swapy jsou typicky umístěny na pomalých discích (v porovnání s rychlostí RAM), tak dojde k tomu, že každý proces co se přesune z RAM do swapu se začne plůžit. To typicky spustí spirálu, že další procesy, které navazují na zpomalené procesy z RAM se začnou taky plůžit a systém se začně pomalu bortit. Velké pozor je potřeba dávat u diagnostiky OOM loadů, pokud totiž systém zapisuje na swap a swap je na discích, snadno se diagnostika a debug zamění s I/O loadem. Proto před diagnostikou OOM loadu je vhodné se podívat v příkazu top na stav RAM
MiB Mem : 8985.5 total, 4336.9 free, 2261.0 used, 2387.6 buff/cache
MiB Swap: 3814.0 total, 3802.7 free, 11.3 used. 5592.9 avail Mem
u Mem i Swap vidíme hodnoty:
total: celková kapacita
free: kolik je volné a nevyužité RAM
Used: použitá RAM.
Především hodnota used vede často ke zmatení, protože nám to nic neříká o tom, jak je s daty vně RAM nakládáno. Ponoříme-li se trochu hlouběji do teorie jak linuxové systému pracují s cache, uvidíme důvod, čím to.
2.2.1 Souborová cache u linuxových systémů
Když je přistupováno k souboru, linuxový kernel si jej uloží dočasně do své RAM a když jej nějakou dobu nepotřebuje, tak jej zase odmaže. Pokud je dostatečné množství RAM dostupno, kernel se snaží ukládávat do RAM vše, co jde. Pak když chci znovu přistoupit ke stejnému souboru, už je rychlost přístupu násobně větší a celý systém se začne projevovat pro uživatele vysokou rychlostí práce s daty. Jak systém běží, jednou za čas nějaké jiné procesy potřebuji RAM, tak si kernel odmázne nějaké soubory ke kterým se moc nepřistupuje a uvolní místo na RAM pro procesy. V mnoha ohledech je mnohem lepší nechat kernel aby pracoval s RAM a netrápit jej třeba tvorbou ramdisků. Proto v příkazu top v části used neuvidíme tolik, kolik uvidíme s příkazem free s příznakem -hm (human readable).
➜ ~ free -hm
total used free shared buff/cache available
Mem: 8.8Gi 2.2Gi 4.2Gi 756Mi 2.3Gi 5.5Gi
Swap: 3.7Gi 11Mi 3.7Gi
u Mem vidíme hodnoty:
total: celková kapacita RAM.
user: kolik RAM je použito.
free: kolik je volné a nevyužité RAM.
shared: kolik zdrojů z RAM vně je sdíleno nebo je v rámci různých programů. přistupováno k tomu stejnému obsahu, který se nahcází na daném médiu
buff/cache: Toto je sloučená hodnota dvou hodnot
buffer: kolik je v bufferu pro potřebu kernelu
cache: kolik je v page cache udržováno souborů
avalible: kolik RAM je v případě potřeby dostupno
Pokud máme podezření, že nám RAM dochází, poznáme to tedy nejen na tom, že nám dochází swap ale i v top příkazu u sloupce %MEM u jednotlivých procesů:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
401 mongodb 20 0 1520184 114892 28420 S 0.7 21.9 11:06.30 mongod
409 elastic+ 20 0 4836616 1.3g 22652 S 0.7 22.4 7:10.59 java
491 graylog 20 0 4849688 911716 19772 S 0.7 24.9 10:44.12 java
1 root 20 0 169400 6092 4680 S 0.0 0.1 0:02.04 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
Řešení je problému s OOM load je snadné, stačí navýšit RAM.
2.3 I/O load
I/O load je poslední druh loadu, který se velmi často vyskytuje při zpomalování linuxových systémů a poznáme jej především při zvýšené hodnotě CPU iowait ale pozor, musíme si dát pozor abychom nezaměnili tento jev s OOM loadem. Problematika I/O load je velmi komplexní a byl to pro nás mimo jiné hlavním pilířem problematiky diagnostiky nízkých propustností. O této problematice by bylo možno napsat knihu, ale my se omezíme na nezbytné minimum. Pro lehký úvod do diagnostiky našími základními nástroji pro práci budou:
- iostat
- iotop
2.3.1 iostat
Iostat je poměrně komplikovaný a komplexní nástroj, proto se pro účely tohoto článku omezíme na nezbytné minimum. iostat nám ukazuje základní vstupní a výstupní statistiky. Iostat není součástí většiny dsitribucí a je potřeba jej doinstalovat přes balíček sysstat. Výpis rozšířeného iostatu vypadá takto:
➜ ~ iostat -xh
Linux 4.19.0-16-amd64 (ispconfig.cnnc.cz) 04/03/2021 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
2.2% 0.0% 1.4% 0.2% 0.0% 96.2%
r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util Device
0.72 1.93 17.9k 40.4k 0.00 2.51 0.4% 56.6% 0.55 2.11 0.00 24.9k 21.0k 0.41 0.1% sda
0.79 0.85 9.1k 19.0k 0.00 1.88 0.2% 68.9% 13.46 11.64 0.02 11.5k 22.4k 3.40 0.6% sde
0.06 7.07 1.3k 138.9k 0.00 1.64 0.4% 18.9% 0.56 0.64 0.00 22.5k 19.7k 0.27 0.2% sdc
0.00 0.00 0.1k 0.0k 0.00 0.00 0.0% 10.5% 0.42 0.74 0.00 27.8k 3.2k 0.32 0.0% sdb
0.00 0.00 0.1k 0.0k 0.00 0.00 0.0% 36.2% 0.39 0.78 0.00 25.0k 5.9k 0.32 0.0% sdd
v hlavičce opět vidíme sumu avg-cpu podobně jako v topu. mnohem zajímavější je obsah, ze kterého vysbíráme jen pro nás to podstatné. Před samotným výpisem prefix r je pro čtení a prefix w je pro zápisy:
r/s: počet sloučených požadavků na čtení za sekundu
w/s: počet sloučených požadavků na zápis za sekundu
rsec/s: Počet čtení na sektor za sekundu
wsec/s: Počet zápisů na sektor za sekundu
rrqm/s: počet sloučených požadavků na čtení za sekundu které byly ve frontě na zařízení
wrqm/s: počet sloučených požadavků na zápis za sekundu které byly ve frontě na zařízení
areq-sz: Průměrná velikost požadavku k zápisu než bude zpracován.
await: Průměrná doba v ms, pro požadavky (read nebo write) než dojde k jejich odbavení
aqu-sz (dříve avgqu-sz): průměrná doba jakou požadavek na strávil ve frontě než byl odbaven.
svctm: Pozor – S tímto bodem už nemá smysl pracovat, do budoucna bude odstraněn.
%util: Jak moc je dané zařízení vytíženo v procentech.
Device: O jaké zařízení se jedná
Pro potřeby I/O CPU debugu nás nejdříve budou zajímat pouze tři hodnoty:
- Device
- Util
- %iowait
Tyto nám napoví, zdali se jedná o iowait a pak jaký disk je vytížen a jak moc je disk vytížen. Jak vidíme, iostat není sám o sobě dostatečný nástroj. Potřebujeme něco více.
2.3.2 iotop
Iotop je analog top příkazu pro i/o operace a velmi nám pomůže s hledáním procesu, který nám vytěžuje stroj.
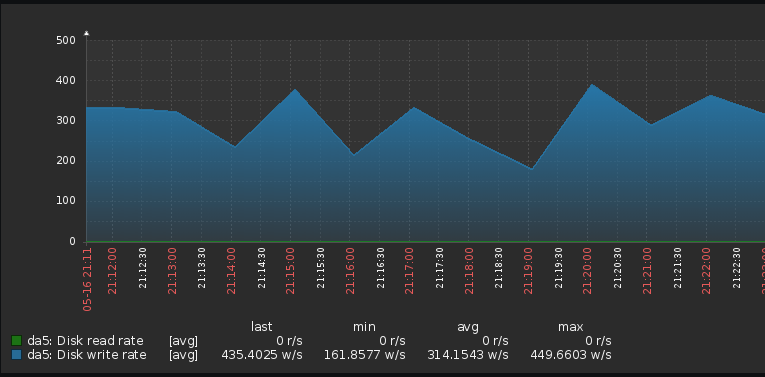
Ve výstupu vidíme vcelku jednoznačný popis celkového čtení, celkových zápisů, aktuálního čtení a aktuálních zápisů.
Total DISK READ: 0.00 B/s | Total DISK WRITE: 31.20 K/s
Current DISK READ: 0.00 B/s | Current DISK WRITE: 54.60 K/s
Pod nimi již vidíme jednotlivé procesy a hodnoty zápisu/čtení.
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
561 be/4 mongodb 0.00 B/s 7.80 K/s 0.00 % 0.08 % mongod --config /etc/mongod.conf [WTJourn.Flusher]
215 be/3 root 0.00 B/s 0.00 B/s 0.00 % 0.06 % [jbd2/sda2-8]
758 be/4 graylog 0.00 B/s 3.90 K/s 0.00 % 0.03 % java -Xms1g -Xmx1g -XX:NewRatio=1 -se~/server/server.conf -np [scheduled-25]
568 be/4 mongodb 0.00 B/s 15.60 K/s 0.00 % 0.00 % mongod --config /etc/mongod.conf [ftdc]
582 be/4 elastics 0.00 B/s 3.90 K/s 0.00 % 0.00 % java -Xms1g -Xmx1g -XX:+UseConcMarkSw~/elasticsearch.pid --quiet [VM Thread]p
Řešení není úplně triviální a je na diskuzi. Může to být závada na disku, závada na řadiči, nízké propustnosti na switchích, přesycené pole které nestíhá práce s nějakou aplikací anebo i mnoho dalších jevů.
Poděkování patří našemu dlouhodobému zákazníkovi za realizaci této zakázky, bez které by tento příjemný blogpost nevznikl.
Nakoukněte co vše umíme dále 😉
Výstavby DNS serverů
Jedná se o velmi častou problematiku, která je žádána jako alternativa k ADDC. Výstavba DNS serverů v redundanci na OS Debian a OS CentOS s užitím BINDu.

VPN koncentrátory na MikroTiku
Výstavba VPN koncentrátorů pro potřeby zasíťování více poboček se směrováním na jednu centrální kancelář.

Diagnostiky nízké propustnosti
Velmi často je řešena problematika diagnostiky nízkých propustností, kde hlavním pilířem je hledání bottlenecku v infrastruktuře, který může být na více místech.

Dokumentace výrobních linek
Ukázka řešení základní problematiky topologického mapování a dokumentace infrastruktury ve výrobních společnostech.

Upgrade infrastruktur
Rozsáhlé aktivity při upgrade celé infrastruktury na nejnovější verze OS a to tak, aby vše bylo sladěno a zkoordinováno bezvýpadkově pro celou společnost.

Výstavba Proxmoxových serverů
Poměrně častou problematikou společnosti je dodávka infrastuktury na klíč. Naším oblíbeným hypervizorem je Proxmox a tento druh problematiky je velmi často žádán.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}