Na poli virtualizačních technologií v dnešní době existuje mnoho různých řešení, které splňují vcelku variabilní potřeby ve firemním segmentu.
V rámci práce u zákazníka jsme se snažili maximálně vyjít vstříc provést upgrade infrastruktury o jeden level a zachovat přitom cenově přijatelnou hladinu řešení. Napřed si ale povězme něco o přirozenosti cyklu u zákazníka, abychom lépe pochopili návaznosti a potřeby v kontextu k prostředí.
Společnost nese hned několikero prvků. Na první pohled může připadat, že společnost nese prvky přirozenosti běžné pro typické výrobní společnosti, ale s významným přesahem a podnikatelskou aktivitou bychom ji mohli lépe charakterizovat spíše jako obchodně-inženýrskou společnosti. V rámci vnitřní infrastruktury se vyskytuje častá potřeba strukturu nafukovat a případně zmenšovat, což je zase běžné u startupových společností. Tedy definice není úplně snadná a potřeby musí být pružné. Hledání řešení se může zdát na první pohled komplikované a bez této znalosti by bylo náročnější porozumět proč jsme vybrali hyperkonvergenci jako jasného kandidáta do budoucna.
Původní stav
Primární serverovna nesla prvky typické pro výrobní společnosti. Tedy několikaserverový cluster napojený na jeden shared storage. Jako disaster recovery (dále DR) byla v geograficky oddělené lokalitě umístěna další struktura typu server-storage. Zálohování probíhalo pomocí odlévání snapshotů celého primárního pole na sekundární pole. Dané nasazení mělo mnoho předností (centralizace, rychlost), ale také technologické nevýhody. Největším bottleneckem celé infrastruktury byl právě storage na primární lokalitě, který nebyl v high avalibility (Dále HA). Tedy v praxi – servisování tohoto pole znamenalo dočasný výpadek celé společnosti a všech přidružených dceřiných společností. Při posuzování stavu jsme dospěli k závěru, že povýšení stávající struktury server-storage na HA storage by bylo velmi nákladné řešení, a vzhledem k zastarávající infrastruktuře by to nebyla ani ekonomicky racionální investice pro zákazníka. Zajímavou volbou pak byla možnost zvážit hyperkonvergenci a na tu jsme na závěr také vsadili. Z různých řešení různých výrobců jsme hledali takový setup, který:
- By nás nezatěžoval certifikovaným hardwarem.
- Měl veřejně dostupné zdrojové kódy (open source), ale s otevřenou a živou komunitou přispěvatelů.
- Měl dostatečnou enterprise podporu v případě nutnosti.
- Byl dostatečně vyzrálý do firemního prostředí.
- Dokázal zajistit stabilní prvky, na kterých postavíme hyperkonvergenci.
- Byl jednoduchý a elegantní (vysvětlíme si později)
- Byl cenově přijatelný.
- Dokázal mít přesah do budoucnosti (tedy primárně do dnešního světa DevOps)
Ze znalostí výše uvedeného filtru jsme usoudili, že na trhu nám vyšla nejlepší kombinace technologií Proxmox (dále PVE) + CEPH + Proxmox backup server (dále PBS). Všechny zmíněné technologie mají své výhody i nevýhody, ale naším cílem bylo abychom udělali maximum a poskládali tyto technologie tak, aby nevýhody byly potlačeny vhodným setupem a nechali jsme vyniknout pro potřeby zákazníky hlavní výhody celého komplexu řešení. Nebudu napínat, povedlo se nám to. Pojďme se podívat, jak jsme na to šli.
Schéma původní infrastruktury
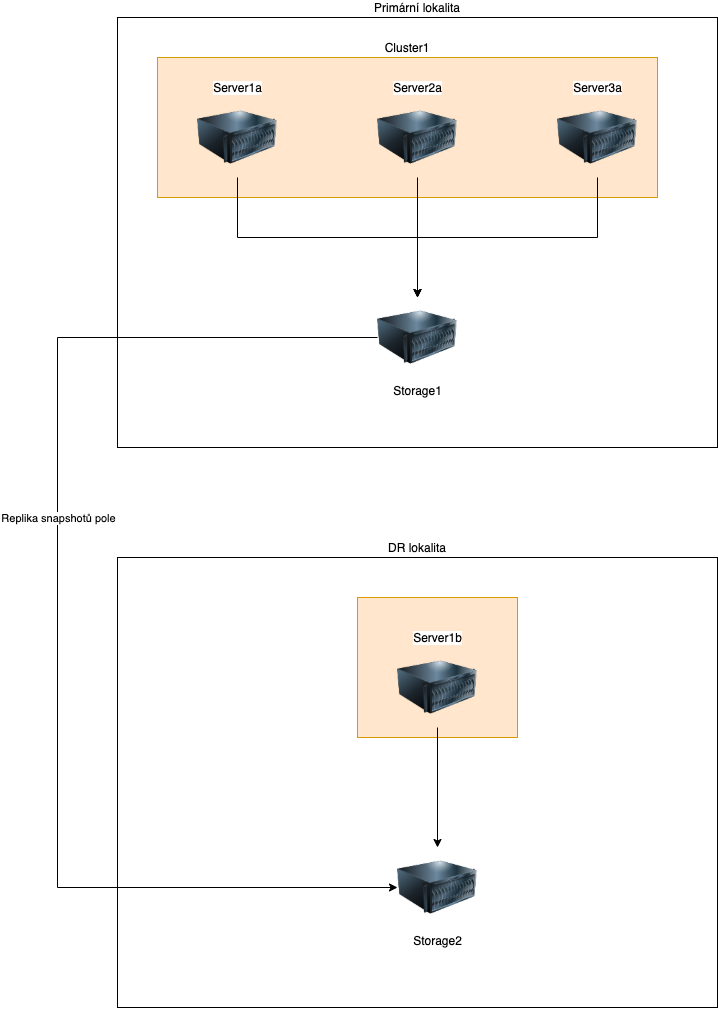
Nový stav
Konfigurace jedné buňky CEPHu
Setup pro typický server v CEPH clusteru jsme zvolili především s ohledem na jednoduchost servisovatelnosti a přitom maximální utilitaci hardware s přihlédnutím k potlačení technologických nevýhod a přesahem k možné automatizaci do budoucna. Proto jsme jako základní buňku clusteru zvolili model, kdy na každém serveru je nejen computing, ale i storage současně. Pak nám pro začátek deploymentu postačili pouze 3 servery a už nyní víme, že dle toho jak bude společnost růst či klesat, tak postupně budeme přidávat či ubírat další servery. Elegantní a jednoduché!
V rámci nasazení jednoho node jsme v provedli konverzi serverů a zakoupili do nich NVMe disky, které jsme osadili do všech PCIExpress slotů. Tím jsme i navždy odstranili z infrastruktury budoucí potřebu mít prvek, se kterým se většina jiných společností potýká – s hardware řadiči, které jsou z dnešního pohledu přežitek a noční můra každého IT správce. Komunikace po PCIExpress sběrnici patří mezi nejrychlejší komunikační kanály a samotné NVMe Disky jsou výborné v tom, že dokáží unést současně zápisy i čtení bez ztráty latence. Abychom udrželi jednoduchost, tak každý server je osazen dvěma SataDOM disky pro samotný hypervizor a pod pokličkou je náš oblíbený ZFS (zettabyte filesystem). Tyto disky opět vynikají svojí jednoduchostí, praktičností práce s nimi a velmi nízkou cenou. Mají své nevýhody, ale ty jsme jak jsem avizoval v úvodu, tak jsme je racionálně odstranili tvorbou elegantního setupu. Jak? Třeba tak, že servery jsou doslova přesycené RAM, proto nemusíme řešit swap místa a zrovna SataDOM nejsou nejlepší jako swap zařízení.
Servery jsme povýšili zatím na 10GB síť a dali jsme je do clusteru do CEPHu. Proč CEPH?
CEPH
(Čte se jako “ceph”, nebo “sef”, nebo “sept”)
CEPH jako takový je mladý a unikátní projekt, který vznikl “teprve” v roce na 2005 na akademické půdě a dostal se velmi rychle do praxe právě kvůli svojí narůstající popularitě. Není to dokonalé řešení, ale má obrovské množství předností a technologických výhod. Pro jednoduchost tohoto článku se nebudeme do detailu zabývat technologickými podrobnosti, řekneme si je pouze obecně.
Když to zkusím ještě lépe připodobnit co je to CEPH, tak to ukáži na analogii. Představte si RAID6 pole. Je odolné vůči výpadku dvěma disků. A nyní si představte něco jako RAID6 mezi servery. Prostě padnou mi dva servery a celá infrastruktura funguje. Tak nějak vypadá prakticky CEPH v nasazení v menším firemním prostředí (2000+ uživatelů infrastruktury je dle autora malé firemní prostředí).
CEPH jako takový je pro jednoduchost tohoto článku je vlastně pole, které je cílené na práce s velkými daty.
A proto má i odlišnou a na první pohled vcelku komplexní sumu malých prvků unitř a pro tento článek je nebudeme zmiňovat.
Jeho síla tkví v několika bodech, třeba:
- v univerzálnosti (můžeme ho nasadit na libovolný hardware)
- Vysoké redundanci (odolnost proti výpadku n serverů)
- Sebemanagementu (CEPH se sám řídí)
- Sebeopravě (CEPH se sám opravuje)
- Distributovatelností dat (Data se distribuuji pseudonáhodně po všech strojích v CEPH – pomocí CRUSH mapy)
- Mohutné rychlosti (s trochou aproximace se dá říct, že s počtem serverů roste i rychlost celého CEPH lineárně)
Běžne ve firmách můžeme pracovat na tradičním poli typu
- Blokové zařízením (typicky LUN)
- Síťové filesystémy (Typicky NFS)
- Filesystémy (typicky SAMBA share pro doplnění)
Jak u těchto protokolů víme, tak volba je vždy kompromis mezi rychlostí a pohodlím. Nejrychlejší zařízení jsou bloková, ale těžko se s nimi pracuje. Nemají filesystem a hezkou adresářovou strukturu. Na druhou stranu SAMBA má hezkou adresářovou strukturu, jenže je pomalá. A volba řešení světí prostředky k dosažení cíle.
Stejně i CEPH má pro tyto případy své blízké analogy z tradičního světa:
- RADOSGW – Objektově orientovaný storage typu S3 (známe jej podvědomě z Amazonu a zde vidíme první krůčky směr k DevOps světu)
- RADOS (analog blokového zařízení)
- CephFS (analog NFS)
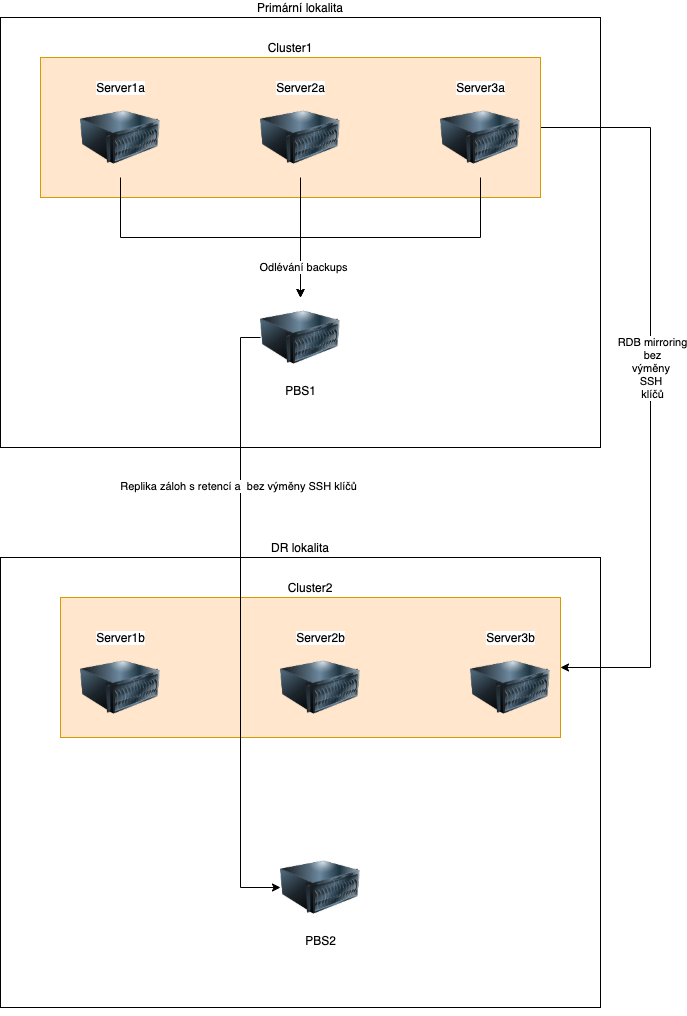
CEPH umí nejen snapshoting, ale pro naši potřebu umí RDB-mirroring. Tedy kdy na geograficky oddělenou lokalitu bez potřeby výměny SSH klíčů dokáží přenášet jednotlivé bloky dat na jiný cluster. A přesně toho jsme s oblibou využili pro potřeby zákazníka, abychom mu dodali geograficky oddělenou zálohu s rychlostí obnovy celé produkce do 5 minut.
Mezi další výhody CEPHu, nebo řekněme software definovaného pole (dále SDS) jsme pro našeho zákazníka vybrali model práce s RADOS Volili jsme jednoduše rychlost a nevýhody jsme potlačili pomoci PBS.
Proxmox backup servery – Výstava zálohování
Pro zálohování jsme zvolili relativně nové řešení na trhu. Ve světě KVM virtualizace si PBS představme jako analog k Veeam backup and replication řešení známe ze světa VMWare. PBS je přesně to, co velmi dlouho PVE chybělo a vyplnilo nám i naši potřebu u zákazníka.
PBS umí:
- Deduplikace (šetří to prostor)
- Vysokou rychlost zálohování (odzálohuje nám 30 strojů o průměrné kapacitě 200GB v průměru do 30 minut)
- Pomocí ZFS nám zajistí vysokou konzistenci dat, možnosti snapshotování a velmi efektivní práci s polem, který významně zrychluje celý proces zálohování (s použitím SLOG devices, L2ARC cache či special devices)
- Pomocí verifikace ověřuje kvalitu provedeného zálohování
- Pomocí garbage collection/pruning zajistí kvalitní pročištení starých záloh.
- Pomocí remotes zajistí geograficky oddělené zálohování v případě havárie.
- Umí provést obnovu jednoho konkrétního souboru
Takto jsme u zákazníka umístili primární PBS přímo v DC s hlavním clusterem a sekundární jsme umístili do DR lokality a replikujeme na něj data z primárního PBS. Všechno (tedy RDB mirroring i PBS replikace) provádíme bez výměny klíčů. Jedná o velmi odolné řešení proti ransomware se schopností obnovy celé infrasturktury v řádech minut a za zlomek ceny, kterou bychom jiných dodavatelů software řešení očekávali. Jak je vidět, nenechali jsme nic náhodě a i obnovu jsme zvolili ve dvojici.
Schéma nové struktury
Overview a závěr
Infrastruktura z dnešního pohledu není jen kus železa, je to koupě do budoucnosti. U tohoto dodaného setupu jsme se snažili maximálně o:
- Jednoduchost
- Eleganci
- Potlačení nevýhod
- Zvýraznění výhod
- Obecnost
Povedlo se nám uspokojit potřebu zákazníka? Ano, povedlo. A s nadhledem vidíme hned několik desítek kroků, co dál v budoucnu s takovou infrasturkturou. Chceme být připraveni na to, jak se trh IT vyvíjí, vyzrává a dozrává. Dnes se pojem DevOps postupně dostává do povědomí i v tradičních firmách a je jen otázkou času, než Kubernetes bude stejně dostupná technologie pro běžného IT správce jako je dnes tradiční virtualizace. Naše řešení s tímto počítá. Ona rovnice Proxmox + CEPH = OpenStack je další logický krůček co napovídá, kam můžeme dále směřovat . OpenStack je forma privátního cloudu a to je přesně jeden z těch významných prvků, který se v potřebách pomalu i u našeho zákazníka začal vyskytovat. Nebude tomu jinak i u ostatních firem a od toho jsme zde my, abychom jim pomohli udělat první krůčky ve světě těchto technologií a dovedli je k úspěchu.