CEPH deployment basics
In the field of virtualization technologies, there are many different solutions available today that can meet the variable needs of businesses.
In our work with clients, we strive to provide maximum flexibility and affordability when upgrading infrastructure. First, however, let us discuss the nature of the customer cycle in order to better understand the context and needs of the environment.
The company embodies several elements. At first glance, it may seem that the company embodies natural elements common to typical manufacturing companies, but with significant overlap and entrepreneurial activity, it would be better characterized as a business-engineering company. Within the internal infrastructure, there is often a need to inflate and potentially shrink structures, which is common in start-up companies. Therefore, the definition is not entirely easy and needs must be flexible. Finding solutions may seem complicated at first glance and without this knowledge, it would be more difficult to understand why we chose hyper-convergence as a clear candidate for the future.
Original state:
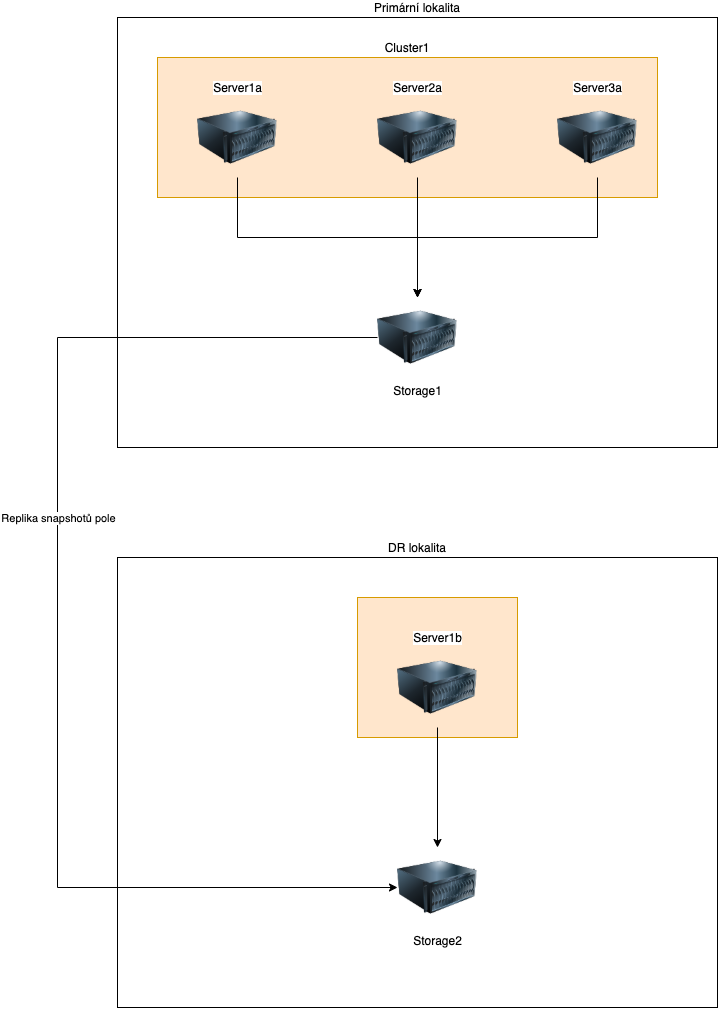
The primary server room contained elements typical of manufacturing companies: a multi-server cluster connected to a single shared storage. Another server-storage structure was located in a geographically separated location as a disaster recovery (DR). Backups were done by copying snapshots of the entire primary array to the secondary array. This deployment had many advantages (centralization, speed), but also technological disadvantages. The biggest bottleneck of the entire infrastructure was the storage at the primary location, which was not in high availability (HA). Therefore, in practice, servicing this array meant a temporary outage of the entire company and all associated subsidiaries. After evaluating the situation, we concluded that upgrading the existing server-storage structure to HA storage would be a very expensive solution, and given the outdated infrastructure, it would not be an economically rational investment for the client. An interesting option was to consider hyper-convergence, and we ultimately chose it. From various solutions from different manufacturers, we looked for a setup that:
- would not burden us with certified hardware
- had publicly available source code (open source) but with an open and active community of contributors
- had sufficient enterprise support if necessary
- was sufficiently mature for the business environment
- could provide stable elements on which to build hyper-convergence
- was simple and elegant (we will explain later),
was affordable
could have an impact in the future (primarily in the world of DevOps)
Based on the above knowledge filter, we concluded that the best combination of technologies on the market for us was Proxmox (PVE) + CEPH + Proxmox Backup Server (PBS). All mentioned technologies have their advantages and disadvantages, but they form a coherent unit for a hyper-convergent solution.
Original Infrastructure Diagram
New State
Configuration of a single CEPH cell
We chose the setup for a typical server in the CEPH cluster primarily with a focus on simplicity of maintenance and maximum hardware utilization while also considering the suppression of technological disadvantages and potential automation in the future. Therefore, we chose a model for the basic unit of the cluster where each server has both computing and storage at the same time. For the initial deployment, we only needed three servers, and now we already know that as the company grows or shrinks, we will gradually add or remove additional servers. Elegant and simple!
As part of the deployment of one node, we converted the servers and purchased NVMe disks, which we installed in all PCIExpress slots. This permanently eliminates the need for an element that most other companies struggle with in their infrastructure – hardware controllers, which are now considered outdated and a nightmare for any IT administrator. Communication over the PCIExpress bus is one of the fastest communication channels, and NVMe disks themselves are excellent in that they can handle simultaneous writes and reads without losing latency. To maintain simplicity, each server is equipped with two SataDOM disks for the hypervisor itself, and underneath the cover is our favorite ZFS (Zettabyte Filesystem). These disks also excel in their simplicity, practicality in working with them, and very low cost. They have their drawbacks, but as I mentioned at the beginning, we have rationally eliminated them by creating an elegant setup. How? For example, servers are literally saturated with RAM, so we don’t have to worry about swap space, and SataDOMs aren’t the best as swap devices.
We have upgraded the servers to 10GB network and added them to the CEPH cluster. Why CEPH?
CEPH
(Pronounced as “ceph” or “sef” or “sept”)
CEPH itself is a young and unique project that was “only” founded in 2005 in an academic environment and quickly made its way into practice due to its growing popularity. It is not a perfect solution, but it has enormous advantages and technological benefits. For the simplicity of this article, we will not go into technical details, we will only discuss them generally.
If I try to better compare what CEPH is, let me use an analogy. Imagine a RAID6 array. It is resistant to the failure of two disks. And now imagine something like RAID6 between servers. Simply put, if two servers fail, the entire infrastructure will still function. This is what CEPH looks like in practical use in a smaller business environment (according to the author, a small business environment with 2000+ users of the infrastructure).
CEPH, as it stands, is a field that targets working with large amounts of data. Its strength lies in several points, such as: 1. its universality (it can be deployed on any hardware)
2. high redundancy (resistance to the failure of n servers),
3. self-management (CEPH manages itself), self-repair (CEPH repairs itself)
4. distributed data (data is distributed pseudorandomly across all CEPH machines using a CRUSH map)
5. Massive speed (with a little approximation, it can be said that the speed of the entire CEPH grows linearly with the number of servers)
In companies, we usually work with traditional types of devices, such as
- Block devices (typically LUN)
- Network file systems (typically NFS)
- File systems (typically SAMBA share for supplementing).
CEPH also has its analogies in the traditional world for these cases, such as
- RADOSGW – S3 Object-oriented storage (known subconsciously from Amazon, and here we see the first steps towards the DevOps world)
- RADOS (analogous to block devices)
- CephFS (analogous to NFS)
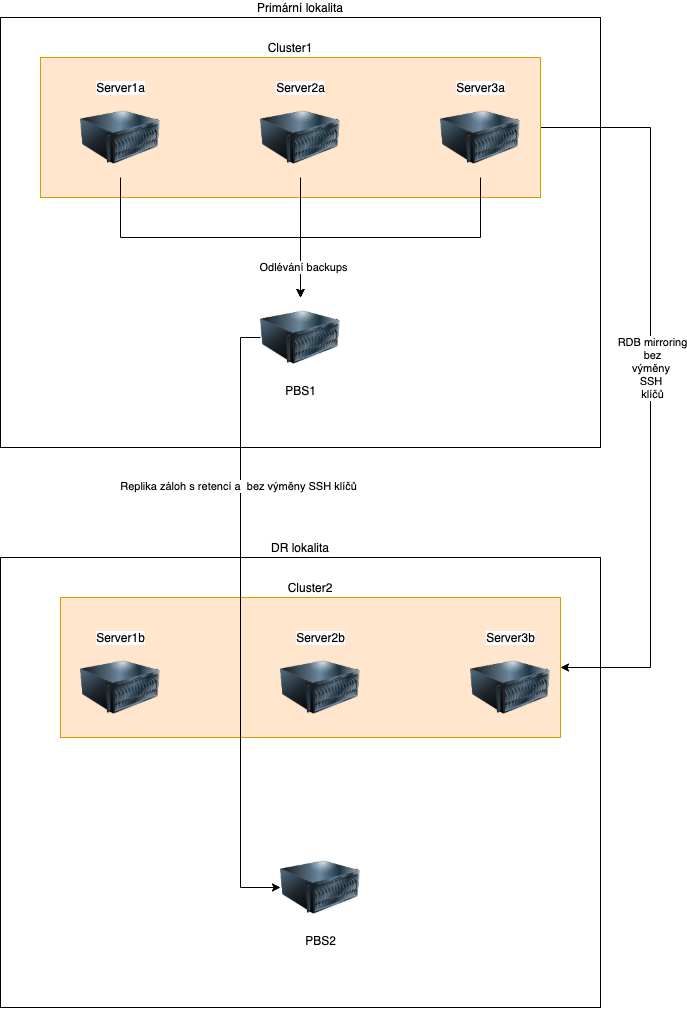
CEPH not only allows for snapshotting but also RDB-mirroring, which means that individual data blocks can be transferred to another cluster on a geographically separated location without the need for an SSH key exchange. We have used this capability to provide a geographically separated backup to a customer with a recovery speed of the entire production within 5 minutes.
For our customer, we chose the RADOS model for working with CEPH, which is a software-defined field (SDS). We chose this model simply for its speed, and we suppressed the disadvantages using PBS.
Proxmox backup server – making the backups powerful
For backup purposes, we chose a relatively new solution on the market, namely PBS, which is an analog to Veeam backup and replication, known from the world of VMWare. PBS is precisely what PVE lacked for a long time and also filled our customer’s needs.
PBS can:
- Deduplicate data (saves space)
- Provide high backup speed (can backup 30 machines with an average capacity of 200GB each in 30 minutes)
- Ensure data consistency, provide snapshot capabilities, and work efficiently with the array, which significantly speeds up the entire backup process (using SLOG devices, L2ARC cache, or special devices)
- Verify backup quality with verification
- Perform garbage collection/pruning to ensure quality cleanup of old backups
- Provide geographically separated backup in case of disaster using remotes
- Perform file-level restore
We installed the primary PBS directly in the DC with the main cluster for the customer, and we placed the secondary PBS in a DR location and replicated the data from the primary PBS to it. We perform everything (RDB mirroring and PBS replication) without exchanging keys. This is a very resilient solution against ransomware with the ability to restore the entire infrastructure in minutes and at a fraction of the cost that we would expect from other software solution providers. As you can see, we did not leave anything to chance, and we chose a paired approach for recovery.
New structure diagram.
Overview and Conclusion
Infrastructure, from today’s perspective, is not just a piece of iron; it is an investment in the future. With this delivered setup, we aimed to achieve maximum:
- Simplicity
- Elegance
- Suppression of disadvantages
- Highlighting of advantages
- Generality
Have we satisfied the customer’s needs? Yes, we have. With a long-term perspective, we see many further steps that we can take with such infrastructure. We want to be prepared for how the IT market is evolving, maturing, and growing. Today, the concept of DevOps is gradually becoming known even in traditional companies, and it is only a matter of time before Kubernetes becomes as accessible to the average IT administrator as traditional virtualization is today. Our solution takes this into account. The equation Proxmox + CEPH = OpenStack is another logical step that indicates where we can move forward. OpenStack is a form of a private cloud, which is precisely one of the significant elements that has slowly begun to appear in the needs of our customers. It will be no different for other companies, and that is where we come in to help them take their first steps in the world of these technologies and lead them to success.